在前边章节中,我们学习了如何使用 spring cloud 搭建微服务,随着服务越来越多,一旦服务出错,定位很难,所以我们就需要有一个能够快速直观的监控服务机制,本节要学习的 sleuth 就是这样一款分布式跟踪工具。
假如我们已经有 3 个服务,它们之间的调用关系为 service1 调用 service2 ,service2 调用 service3 。要使用 sleuth 来监控他们的调用链只需要加上 sleuth 的依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
之后我们就会在控制台看到有类似 [service1,84caca7a1662da40,84caca7a1662da40,false] 的日志,sleuth 对调用链的监控就是靠这个实现的。那么这些日志都是什么意思呢?这就涉及到 zipkin 的基本概念了。
- traceId
就是一个全局的跟踪 ID ,用来标识一条调用链。 - spanId
一个 span 可以看成是一次调用,spanId 就是这次调用的 ID 。 - parentId
上一次调用的 ID,用来将前后的请求串联起来。 - cs(client send)
客户端发起请求,在 span 开始的时候设置。 - sr(server receive)
服务端收到请求之后开始处理请求之前。sr 和 cs 的时间差就是网络延时。 - ss(server send)
服务端处理完成并返回给客户端。ss 和 sr 的时间差就是服务器处理的时长。 - cr(client receive)
客户端收到响应,在 span 结束的时候设置。cr 标识着一次请求完成。
了解了这些基本概念,再结合日志我们就可以搞清楚 sleuth 的处理过程了。
[serviceName,traceId,spanId,upload]
[service1,8412e2eebe56a8c0,8412e2eebe56a8c0,true]
[service2,8412e2eebe56a8c0,ced32b7682dfb002,true]
[service3,8412e2eebe56a8c0,fecfced41b92ee72,true]
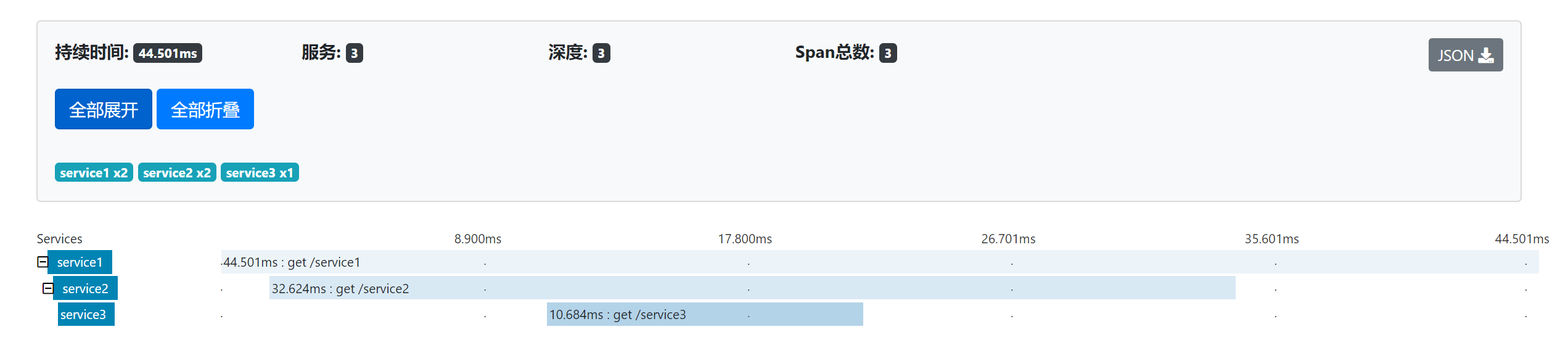
当我们请求 service1 时,由于这是一个新的请求,所以首先会生成一个随机的 traceId 和 spanId 8412e2eebe56a8c0,parentId 为空,当 service1 调用下游的 service2 时,会生成一个新的 span 同时生成一个新的 spanId ced32b7682dfb002 ,但会使用相同的 traceId 8412e2eebe56a8c0 ,service1 的 spanId 8412e2eebe56a8c0 会作为 service2 的 parantId 。service2 调用 service3 处理逻辑也是一样的。Trace 的信息就会通过这样的方式从上游服务 service1 一直传递到下游服务 service3 ,直到整个调用链结束。
有了这些跟踪信息,在通过可视化的组建 zipkin 就可以直观的监控调用链的信息了。下面我们就来看看如何使用 zipkin 收集 sleuth 的日志信息。
首先在服务中加入依赖。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
</dependency>
添加 zipkin 配置。
spring:
zipkin:
base-url: http://localhost:9411
然后启动一个 zipkin-server ,以 docker 为例。
docker run -d -p 9411:9411 openzipkin/zipkin
访问 http://localhost:9411/zipkin/ 可以看到 zipkin-server 的界面。然后我们请求 service1 ,日志出现 [service1,249309b6a4120e9f,249309b6a4120e9f,false] 类似日志,最后一位表示是否采样,就是是否被 zipkin 收集,false 表示未收集,访问第 10 次就会输出一条 true 的日志(和采样率 spring.sleuth.sampler.probability 有关,默认是 10%),这时我们在 zipkin 中就能够查询到调用链的信息了。