什么是机器学习?
在不直接针对问题进行编程的情况下,赋予计算机学习的能力。–来自 1959 年 Arthur Samuel 。
机器学习的分类
监督学习
算法的输入训练数据集包含了某种程度上的“标准答案”,通过找到“标准输入”和标准答案“之间的关系,尝试在给出新的输入时得到更准确的答案。
监督学习有常见的2种分类:回归和分类。
回归问题处理的数据是连续的,分类处理的数据是离散的。
无监督学习
算法的输入训练数据集不包含任何“标准答案”,尝试寻找数据中的联系。
聚类是最常见的无监督学习。
工程应用中使用机器学习需要哪些步骤?
1. 数据获取及存储
2. 数据清理及转换
- 过滤数据
- 处理缺失,不完整,有缺陷数据
- 处理异常数据
- 合并
- 汇总
3. 模型训练
- 特定问题最优建模方法选择
- 特定模型最佳参数选择
4. 模型测试
评估性能
| 实际\预测 | 1 | 0 | 合计 |
|---|---|---|---|
| 1 | True Positive(TP) | False Negative(FN) | Actual Positive(TP+FN) |
| 0 | False Positive(FP) | True Negative(TN) | Actual Negative(FP+TN) |
| 合计 | Predicted Positive(TP+FP) | Predicted Negative(FN+TN) | TP+FP+FN+TN |
TP(True Positive):指正确分类的正样本数,即预测为正样本,实际也是正样本。
FP(False Positive):指被错误的标记为正样本的负样本数,即实际为负样本而被预测为正样本,所以是False。
TN(True Negative):指正确分类的负样本数,即预测为负样本,实际也是负样本。
FN(False Negative):指被错误的标记为负样本的正样本数,即实际为正样本而被预测为负样本,所以是False。
TP+FP+TN+FN:样本总数。
TP+FN:实际正样本数。
TP+FP:预测结果为正样本的总数,包括预测正确的和错误的。
FP+TN:实际负样本数。
TN+FN:预测结果为负样本的总数,包括预测正确的和错误的。
- 正确率:训练样本中被正确分类的样本数量除以总样本数。
$$
正确率(True Positive Rate)=\frac{TP+TN}{TP+FP+TN+FN}
$$
- 错误率:训练样本中被错误分类的样本数量除以总样本数。
$$
错误率(FalsePositiveRate)=\frac{FP+FN}{TP+FP+TN+FN}
$$
- 准确率:评价结果的质量。
$$
准确率(Precision)=\frac{TP}{TP+FP}
$$
- 召回率:评价结果的完整性。
$$
召回率(Recall)=\frac{FP}{TP+FN}
$$
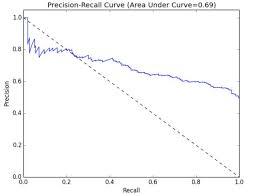
准确率-召回率曲线下方面积
准确率和召回率是负相关的,通常被一起组成聚合或者平均度量,PR曲线下方面积为平均准确率。PR曲线越往右上效果越好。
ROC曲线
和PR曲线类似,表示不同决策阈值下TPR对FPR的折衷。ROC曲线越往左上效果越好。
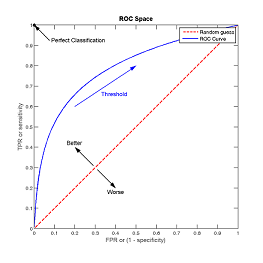
ROC曲线下的面积
ROC曲线下的面积表示平均值,也称作AUC。
F-Measure
综合评价指标是P和R的加权调和平均。
$$
f=\frac{(a^2+1)P\times{R}}{a^2(P+R)}
$$
当a=1时,即为最常见的F1-Measure。
$$
f1=2\times\frac{P\times{R}}{P+R}
$$
5. 模型部署与整合
6. 模型监控与反馈
Spark MLlib
Spark MLlib 是一个机器学习库,包含两部分:
- spark.mllib: 数据类型,算法以及工具
- spark.ml: 机器学习管道高级API
如何使用Spark MLlib编程
// 初始化上下文
SparkConf sparkConf = new SparkConf().setAppName("JavaNaiveBayesExample");
JavaSparkContext jsc = new JavaSparkContext(sparkConf);
// 获得数据
JavaRDD<LabeledPoint> inputData = MLUtils.loadLibSVMFile(jsc.sc(), path).toJavaRDD();
// 训练模型
NaiveBayesModel model = NaiveBayes.train(training.rdd());
// 保存模型
model.save(jsc.sc(), "target/tmp/myNaiveBayesModel");
// 装载模型
NaiveBayesModel sameModel = NaiveBayesModel.load(jsc.sc(), "target/tmp/myNaiveBayesModel");
// 预测
JavaPairRDD<Double, Double> predictionAndLabel =
test.mapToPair(p -> new Tuple2<>(model.predict(p.features()), p.label()));
// 评估性能
double accuracy =
predictionAndLabel.filter(pl -> pl._1().equals(pl._2())).count() / (double) test.count();
jsc.stop();
jsc.close();
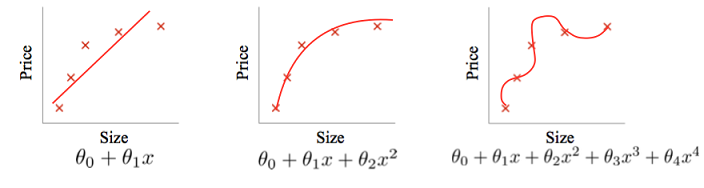
欠拟合和过拟合