
Java BIO 我们已经很熟悉了,它实现起来比较简单,一个线程只能维护一个连接。但是弊端也很明显,即服务器开销大,资源浪费严重。
Java NIO 是在JDK 1.4中引入的。Java NIO 弥补了原来的 I/O 的不足,它在标准 Java 代码中提供了高速的、面向块的 I/O。Java I/O 库与 Java NIO 最重要的区别是数据打包和传输的方式的不同,Java I/O 以流的方式处理数据,而 Java NIO 以块的方式处理数据。
先通过两张图对比一下。

Java NIO 加入了 selector,channel,buffer 三个组件。一个 client 有对应的 buffer ,buffer 有对应的 channel。一个线程维护一个 selector ,一个 selector 可以维护多个 channel。selector 通过事件机制,在多个 channel 间切换,有 IO 操作时,线程可以切换到对应的 channel 进行操作,如果没有 IO 操作,线程还可以做其他工作而不会阻塞,这样就大量的节省了服务器的资源。
下面我们通过代码对 Java I/O 和 Java NIO 进行说明。
/**
* 使用IO读取指定文件的前1024个字节的内容。
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
FileInputStream is = new FileInputStream("GitHub.txt");
byte[] buffer = new byte[8];
is.read(buffer);
System.out.println(new String(buffer));
is.close();
}
/**
* 使用NIO读取指定文件的前1024个字节的内容。
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception {
FileInputStream is = new FileInputStream("GitHub.txt");
//为该文件输入流生成唯一的文件通道 FileChannel
FileChannel channel = is.getChannel();
//开辟一个长度为1024的字节缓冲区
ByteBuffer buffer = ByteBuffer.allocate(8);
channel.read(buffer);
System.out.println(new String(buffer.array()));
channel.close();
is.close();
}
从上边的代码可以看出,Java NIO 的主要使用了 Channel 和 Buffer ,它们是 Java NIO 的核心。FileChannel 和 ByteBuffer 是 Channel 和 Buffer 最常用的实现类。
Java NIO 是 Java I/O 的补充而不是替代,在某些场景使用 Java I/O 要容易很多。例如一次读一行,使用 BufferedReader 的 readLine() 方法很容易,而要使用 Java NIO 则需要自己来判断一行从哪里结束。
Channel
Channel 相当于 Java I/O 的流,Java NIO 所有的操作都由 Channel 开始的。
Buffer
Channel 提供了从源读取数据的渠道,而数据的操作都是由 Buffer 完成的。每个 Buffer 都有 capacity 、limit 、position 、mark 4 个属性。
- capacity
Buffer 的容量 - limit
limit 是 Buffer 操作数据的范围。写数据时,limit 的上限等于 capacity,读数据时,limit 为有效数据的长度。 - position
position 指示了 Buffer 中下一个可操作的数据的位置。 - mark
临时的 position 。
以上边代码为例。当 new 一个 ByteBuffer 时,首先将 capacity 和 limit 的大小都设置为 8 ,mark 为 -1, position 为 0 ,初始化完成 capacity 的大小就不变了。
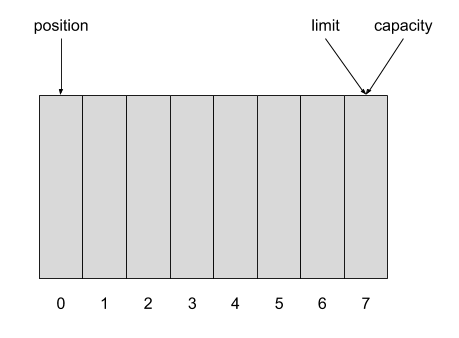
有了 Buffer 就可以开始写数据了。从 Chanel 读 5 个字节到 Buffer 中,position 变为 5 。
现在要从 Buffer 中将数据写到 Chanel 中,需要执行 flip() 方法。执行 flip() 方法后,position 变为 0, limit 变为 5 。
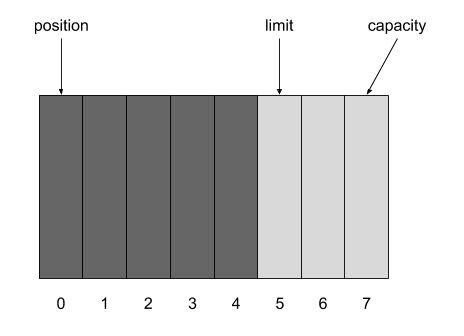
如果 Buffer 中写了 3 个字节到 Chanel 中,如果执行 clear() 方法,剩余的 2 个字节将被丢弃,Buffer 可重新读入数据。如果想保留 2 个字节后续处理,可执行 compact() ,Buffer 将拷贝 2 个字节到起始位置,将 position 置为 2 ,limit 置为 8 。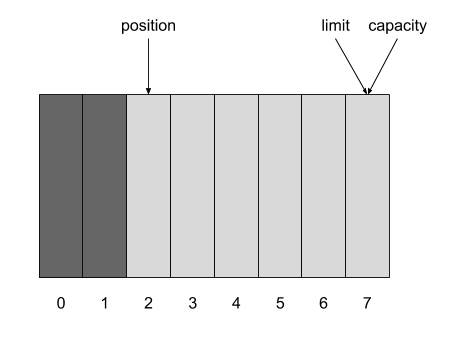
大文件处理
关于 NIO MappedByteBuffer 的例子,我在测试的时候并没有得到和网上资料相同的结果,还不知道原因
Java 中大文件处理通常会使用带缓冲的流,Java NIO 提供了 MappedByteBuffer 来处理大文件。MappedByteBuffer 继承自 ByteBuffer ,它使用 direct buffer 方式来读写文件,这种方式也叫做内存映射,没有 JVM 和操作系统之间的复制操作,直接调用系统底层的缓存,所以效率比较高。
我试了一下用 MappedByteBuffer 的方式复制文件,速度还没有使用 Java I/O 的 Buffered stream 快,不知道问题何在。
public static void foo1() throws IOException {
long start = System.currentTimeMillis();
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(new File("spark-1.6.1-bin-hadoop2.6.tgz")));
BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("spark1.tgz"));
int length;
byte[] buffer = new byte[1024];
while ((length = bis.read(buffer, 0, buffer.length)) != -1) {
bos.write(buffer, 0, length);
}
long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
bis.close();
bos.close();
}
public static void foo4() throws IOException {
long start = System.currentTimeMillis();
String srcFile = "spark-1.6.1-bin-hadoop2.6.tgz";
String destFile = "spark4.tgz";
Path path = Paths.get(srcFile);
FileOutputStream rafo = new FileOutputStream(destFile);
FileChannel fci = FileChannel.open(path,StandardOpenOption.READ,StandardOpenOption.WRITE);
FileChannel fco = rafo.getChannel();
MappedByteBuffer mbbi = fci.map(FileChannel.MapMode.READ_ONLY, 0, path.toFile().length());
fco.write(mbbi);
long end = System.currentTimeMillis();
System.out.println((end - start) + "ms");
fci.close();
fco.close();
rafo.close();
}
只能先理解一下概念。
在操作大文件的时候,如果文件大到无法放到内存,可以用 MappedByteBuffer 映射硬盘文件到内存(不是真放到内存),处理可以简单一些。
网上另一个用法:
int length = 0x8FFFFFF;//一个byte占1B,所以共向文件中存128M的数据
try (FileChannel channel = FileChannel.open(Paths.get("src/c.txt"),
StandardOpenOption.READ, StandardOpenOption.WRITE);) {
MappedByteBuffer mapBuffer = channel.map(FileChannel.MapMode.READ_WRITE, 0, length);
for (int i = 0; i < length; i++) {
mapBuffer.put((byte) 0);
}
for (int i = length / 2; i < length / 2 + 4; i++) {
//像数组一样访问
System.out.println(mapBuffer.get(i));
}
}