
Java Stream 是 jdk 1.8 加入的新 API ,目的是用来支持函数式编程,位于 java.util.stream 包下。
Stream 并不是集合,只是提供了针对于集合的函数式操作,如 Map-Rudeuce 转换。Stream 和集合的区别主要体现在一下几点:
- 不存储数据
Stream 不是一个存储数据的数据结构,相反,它是通过一个计算操作的管道从源(数据结构,数组,I/O管道等)传输数据。 - 操作并不改变源
- 延迟处理
多数 Stream 操作,比如过滤、转换等都不是立即执行的,而是在最佳时机执行。例如,查找第一个有三个连续元音的字符串,Stream 操作分为 中间操作 和 最终操作 , 中间操作始终是延迟处理的。 - 无限的
集合的 size 是有限的,Stream 是无限的。limit(n) 或 findFirst() 等短路操作可以让无限的 Stream 在有限的时间内完成计算。 - 可消耗的
像 Iterator 一样,Stream 中的元素在其生命周期内只能访问一次。
Stream 操作和管道
Stream 操作分为中间操作和最终操作,通过管道的被组合起来。一个 Stream 管道包含一个源,0 个或多个中间操作和一个最终操作。
中间操作会返回一个新的 Stream , 但并不是立即执行的。比如 filter() 方法不会执行过滤,而是在最终操作执行遍历时才创建一个由符合条件元素构成的新 Stream 。
最终操作会产生结果。最终操作被执行后,Stream 管道可以被消耗,并不能再被使用。如果你需要再次遍历相同的数据源,只能获取新的 Stream 。通常最终操作会在返回前完成遍历和计算,除了 iterator() 和 spliterator() 。these are provided as an “escape hatch” to enable arbitrary client-controlled pipeline traversals in the event that the existing operations are not sufficient to the task.
中间操作又分为有状态和无状态。无状态操作处理的元素之间彼此是相互独立的,如 filter 和 map 。有状态操作处理新元素则需要用到之前处理的元素的结果,如 distinct 和 sorted 。有状态操作需要针对全部元素处理得到结果,比如排序。所以在并行计算中,管道包含的中间操作需要多次传递和缓存数据。不论顺序还是并行处理,如果管道只包含无状态操作,则可以使用最少的数据缓存单次完成处理。
对于无限的 stream ,短路操作是必须的。如果中间操作是短路操作,将会返回一个有限 stream 作为结果,如果最终操作是短路操作,将会在有限时间内结束。
并行化
所有的 stream 都可以串行或并行执行,jdk 默认使用串行处理 stream ,如果需要并行,可以指定使用并行方式处理,如 Collection.parallelStream() 。
int sumOfWeights = widgets.parallelStream()
.filter(b -> b.getColor() == RED)
.mapToInt(b -> b.getWeight())
.sum();
上边代码中,串行和并行的唯一区别就是使用 parallelStream() 代替 stream() 。
Non-interference
大多数情况下,stream 操作接受的参数大多是 lambda 表达式,用来描述用户指定的行为。为了保证行为正确,这些参数必须是非干扰和无状态的。
Stream 语法
Stream 语法由源,中间操作和最终操作组成。
从上图(图片来自http://ifeve.com/stream/)可以看出,使用 Stream 的基本步骤:
- 创建 Stream
红色框中语句生成的是一个包含所有 nums 变量的 Stream 。 - 转换 Stream
绿色框中语句把一个 Stream 转换成另外一个 Stream ,原 Stream 不变。 - 对 Stream 进行聚合(Reduce)操作
蓝色框中语句把 Stream 的里面包含的内容按照某种算法来汇聚成一个值。
创建
获得 stream 的方法有如下几种:
- 通过 Collection 的 parallelStream() 和 stream() 方法;
- 通过 Arrays.stream(Object[]) 方法;
- 通过 Stream 的静态工厂方法,如:Stream.of(Object[]), IntStream.range(int, int) or Stream.iterate(Object, UnaryOperator);
- 通过 BufferedReader.lines();
- Stream
可通过 File 类中的方法获得,如:list(Path dir) 或 lines(Path path) 等; - Random.ints() 可获得 IntStream ;
- 其他一下生成 stream 的方法,如:BitSet.stream(), Pattern.splitAsStream(java.lang.CharSequence), and JarFile.stream() 。
转换
- distinct:
对于 Stream 中包含的元素进行去重操作(去重逻辑依赖元素的 equals 方法),新生成的 Stream 中没有重复的元素。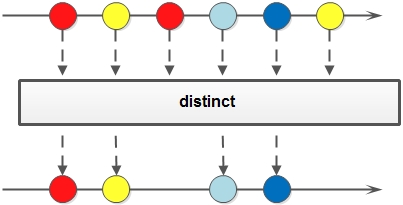
- filter:
对于 Stream 中包含的元素使用给定的过滤函数进行过滤操作,新生成的 Stream 只包含符合条件的元素。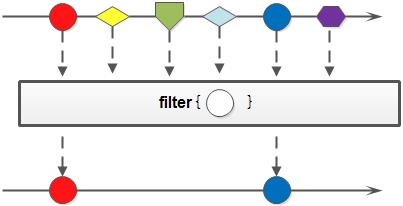
- map:
对于 Stream 中包含的元素使用给定的转换函数进行转换操作,新生成的 Stream 只包含转换生成的元素。这个方法有三个对于原始类型的变种方法,分别是:mapToInt,mapToLong 和mapToDouble 。这三个方法也比较好理解,比如 mapToInt 就是把原始 Stream 转换成一个新的 Stream ,这个新生成的 Stream 中的元素都是 int 类型。之所以会有这样三个变种方法,可以免除自动装箱/拆箱的额外消耗。
- flatMap:
和 map 类似,不同的是其每个元素转换得到的是 Stream 对象,会把子 Stream 中的元素压缩到父集合中。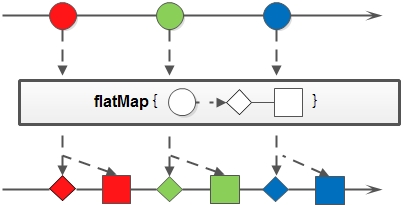
光从文字描述,感觉 flatMap 还是很难理解,通过程序帮助理解。
```java
Stream
);Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6)
nums.flatMap(e -> e.stream()).collect(Collectors.toList()).forEach(e -> System.out.print(e + “,”));
输出结果为
```java
1,2,3,4,5,6,
可以看出 flatMap 的作用是将源 Stream 中的 List 结构去掉,用 List 中的元素构成新的 List 。
peek:
生成一个包含原 Stream 的所有元素的新 Stream ,同时会提供一个消费函数( Consumer 实例)。新 Stream 每个元素被消费的时候都会执行给定的消费函数。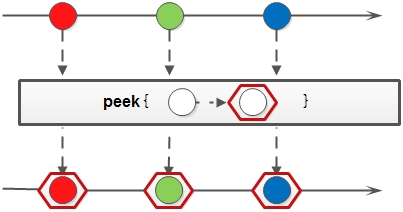
文字描述还是没有程序直观
Stream<List<Integer>> nums = Stream.of( Arrays.asList(1), Arrays.asList(2, 3), Arrays.asList(4, 5, 6) ); nums.peek(e -> System.out.println(e.size())) // 查看每个元素(list)的 size .map(e -> e.get(0)) .collect(Collectors.toList()) .forEach(System.out::print); );peek 字面意思是窥视,通常也多用在 debug 中查看 Stream 的元素内容。
- limit:
对一个 Stream 进行截断操作,获取其前 N 个元素,如果原 Stream 中包含的元素个数小于 N ,那就获取其所有的元素。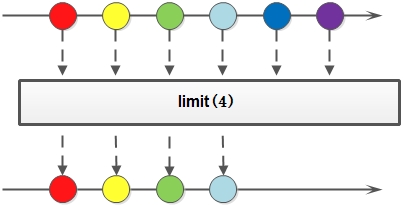
- skip:
返回一个丢弃原 Stream 的前 N 个元素后剩下元素组成的新 Stream ,如果原 Stream 中包含的元素个数小于 N ,那么返回空 Stream。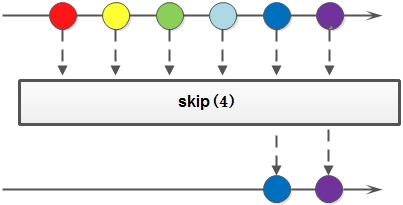
聚合
聚合也叫 fold ,是通过重复的组合操作将一个元素序列合并成单独的结果,比如求 sum 或找到一个数字集合的最大值。Stream 类有多种形式的通用聚合操作,如 reduce() 和 collect() ,还有很多特殊的聚合操作,如 sum() 和 count() ,这些只有 IntStream 、DoubleStream 和 LongSteam 类才有。
在 jdk 1.8 以前,要计算 sum 通常使用 for 循环:
int sum = 0;
for (int x : numbers) {
sum += x;
}
使用 Stream 可以这样写:
int sum = numbers.stream().reduce(0, (x,y) -> x + y);
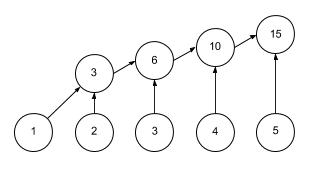
int sum = numbers.stream().reduce(0, Integer::sum);
可变聚合
可变聚合操作是将输入元素聚合到一个可变的结果容器中,如 Collection 或 StringBuilder 。
如果想将 Stream 中的字符串连接成一个长字符串,通常的做法是:
String concatenated = strings.reduce("", String::concat);
collect() 的一般形式是:
<R> R collect(Supplier<R> supplier,
BiConsumer<R, ? super T> accumulator,
BiConsumer<R, R> combiner);
该操作需要 3 个函数:
- Supplier 创建一个新的结果容器的实例;
- accumulator 将输入参数组织到结果容器中;
- combiner 将结果容器中的内容合并生成另一个结果容器。
将集合中的字符串全转成大写:
List<String> list = Lists.newArrayList("a", "b", "c");
List<String> list1 = list.stream().collect(() -> new ArrayList<>(), (c, e) -> c.add(e.toUpperCase()), (c1, c2) -> c1.addAll(c2));
使用标准 Collector 重写:
List<String> list2 = list.stream().map(String::toUpperCase).collect(ArrayList::new, ArrayList::add, ArrayList::addAll);
还有更简化的写法,利用 collect() 的重载方法:
<R, A> R collect(Collector<? super T, A, R> collector);
List<String> list3 = list.stream().map(String::toUpperCase).collect(Collectors.toList());