
HashMap 是最常用的集合类之一,在面试中也出镜率颇高。
HashMap 和 Hashtable
经常会问 HashMap 的特点 及 HashMap 和 Hashtable 的区别 等等,那么就先做一下简单总结。
| HashMap | Hashtable | |
|---|---|---|
| 所在位置 | 实现 Map 接口,JDK 1.2 加入到 Java Collections Framework | Hashtable 集成自 Dictionary ,JDK 1.2 实现了 Map 接口 |
| 是否支持 null key 或 null value | 是 | 否 |
| 线程安全 | 不安全 | 安全 |
以上是 3 点是我们耳熟能详的二者之间的区别,Hashtable 不是我们此篇的重点,暂且放在一旁。
HashMap 的数据结构
上边这个面试题是通常只是开胃菜,每个熟悉 Java 的人都能知晓。上题热身之后,经常会有这样的问题提出: HashMap 是如何存储数据的? Java8 中是通过数组链表和红黑树来实现的。
Java8 中,当我们向 HashMap 中 put 元素时,会进行一下几步操作:
- 首先判断数组是否初始化,如果没有初始化,会首先调用 resize() 对 Node
- 然后通过 hash(key) 定位到数组元素 Node
- 如果 Node
- 如果 Node
- 添加完成,再判断链表中元素的数量是否超过 treeify 的阈值,如果超过则进行 treeifyBin 操作。
- 最后再判断一下 HashMap 中元素的数量是否超过负载值,如果超过则再进行一次 resize() 。

和之前的版本不同,为了避免单个 Node

treeify 操作并不一定会将链表转成树,会根据 HashMap 中元素的数量是否超过 treeify 的最小阈值来决定。
resizing
什么是 resizing ? 我们知道 HashMap 中数组的元素在 Node

将旧的数组扩容成新的数组,旧数组中的元素需要重新放置到新数组中,这个过程不会再重新计算 hash(key) ,而是先遍历链表算出 hiTail 和 loTail ,然后根据 hiTail 和 loTail 得到元素在新数组中的位置。说简单点,由于扩容是向左移一位,那么不用每次都重新计算 hash(key) ,只要看左边新扩展的一位是 0 还是 1 , 0 就留在原位置,1 就将原位置索引加上原容量得到新位置的索引。计算结果参考下图: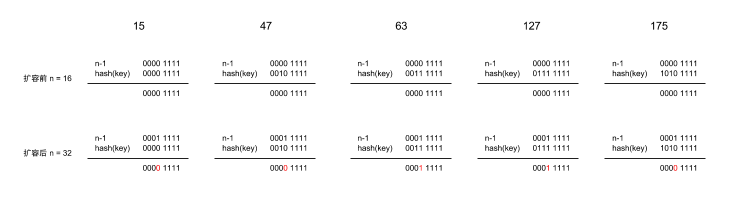
Java8 和之前的版本在实现上有很大的不同。Java8 之前,后加入的元素在链表的头部。Java8 是最先加入的元素在链表头部。
为什么使用 String 作为 key 是一个不错选择?
其实,答案可以从上边获得。因为,String 是 final 的,并且有固定的 hashCode() 和 equals() 方法,所以能有效减少碰撞的发生,同时由于不可变,可以缓存 key 的 hashcode ,提高 get 对象的速度。同理,如果自定义对象作为 key ,应保证对象是不可变的,即保证 equals() 和 hashCode() 方法正确重写。
多线程环境下 resize 导致 CPU 100%
这个是 Java8 之前多线程环境下 HashMap 会出现一个问题,导致问题原因是在链表中后加入的元素会在链表的头部,在扩容通过遍历将旧数组中的元素移动到新数组中,在多线程中有可能出现环形链表,get 的时候导致死循环,最终导致 CPU 100% 。Java8 的 resize 不再使用这种方式,也就不会出现这个问题了。
初始化容量的设计
HashMap 的初始容量为 16 ,容量超过 75% 就会 resizing 。虽然 HashMap 的 resizing 性能在不断提升,但是如果能预估 HashMap 的大小,就能够避免不必要的 resizing 。比如,有 1000 个元素, 下面的写法必定会触发 resizing 。
Map map = new HashMap();
或
Map map = new HashMap(1000);
不考虑空间因素,2 倍 size 是最简单的方法。
Map map = new HashMap(1000 * 2);
但这样并不是太好,因为 HashMap 本身就不省空间。所以靠谱的做法还是自己算一个 init size 。
float size = 1000 / 0.75f;
Map map = new HashMap(size);
或
Map map = Maps.newHashMapWithExpectedSize(1000);
Key 的设计
我们知道 Map 获取元素是通过 Key 来比较的,Integer/String 这些常见的类型都可以作为 key 。这些类都有一个共同的特点,即重写了 hashCode() 和 equals() 方法,保证了 key 的离散,并且这些类是 final 的,保证不会有子类重写这些方法。如果需要使用自定义对象类型的 key ,最好还是要重写 hashcode 和 equals 方法来保证元素分布是离散的。
几种同步的 HashMap 的区别
Hashtable 对方法加 synchronized 。
Collections.synchronizedMap(new HashMap<>()); 使用 synchronized 代码块。
ConcurrentHashMap 利用分段锁,java8 之前是先根据 hash 定位到 segment 然后在 segment 内部使用 lock 加锁。Java8 是对 Node